







 400-806-1508
400-806-1508
数澜科技开设栏目「技术派+」,聚焦前沿技术,洞悉行业风向,分享来自一线的研发经验与应用实践。
本期专栏由数澜科技研发中心副总经理白松带来,分享湖仓一体实践与探索。
随着社会数字化进程不断加快,数据规模、数据类型持续高速增长。为了满足更加复杂的业务数据分析诉求,大数据基础设施技术从数据库、数据仓库、数据湖、再到湖仓一体逐步演化。
而伴随多个领域、场景的成功落地,湖仓一体这一技术概念正式走入了主流视野,AWS、阿里、华为、谷歌、腾讯等大厂纷纷推出基于云技术的数据湖服务产品。在国际知名机构Gartner发布的《Hype Cycle for Data Management 2021》中,湖仓一体(Lake house)首次被纳入到技术成熟度曲线中。
湖仓一体从本质上打破了数据仓库和数据湖之间的壁垒,使得割裂的数据融合统一,减少了数据分析中的搬迁,实现了统一的数据管理,有利于挖掘、发挥更多数据价值。
在展开阐述湖仓一体之前,我们先了解数据湖与数据仓库。
参考维基百科的定义,数据湖是一个存储企业的各种各样原始数据的大型仓库,其中的数据可供存取、处理、分析及传输。数据湖是以其自然格式存储数据的系统或存储库,通常是对象或文件。数据湖通常是企业所有数据的单一存储,包括源系统数据的原始副本,以及用于报告、可视化、分析和机器学习等任务的转换数据。数据湖可以包括来自关系数据库的结构化数据,半结构化数据(CSV、日志、XML、JSON),非结构化数据(电子邮件、文档、PDF)和二进制数据(图像、音频、视频)。
而数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据存储系统,它将来自不同来源的结构化数据聚合起来,用于业务智能领域的比较和分析,数据仓库是包含多种数据的存储库,并且是高度建模的。
数据湖和数据仓库两者的区别如下:
在数据存储方面,数据湖可以存储结构化、半结构化、非结构化的所有数据,而数据仓库只能处理结构化数据。数据仓库在处理数据之前要先进行数据梳理、定义数据Schema后才进行入库操作,而数据湖是将原始数据原样同步进来,这就为后续数据湖的机器学习、数据挖掘带来无限可能。
数据仓库因为模型范式的要求业务不能随便地变迁,但对于数据湖来说,即使像互联网行业不断有新的应用,业务不断发生变化,数据模型也不断地变化,但数据依然可以非常容易地进入数据湖,对于数据的采集、清洗、规范化的处理,完全可以延迟到业务需求的时候再来处理。因此数据湖相对于企业来说,灵活性比较强,能更快速地适应前端业务的变化。
从两者的具体应用来看,数据仓库存储结构化的数据,适用于快速的BI和决策支撑,而数据湖可以存储任何格式的数据,往往通过挖掘能够发挥出数据的更大作为。
虽然数据仓库和数据湖的应用场景和架构不同,但它们并不是对立关系,在一些场景上二者的并存可以给企业带来更多收益,因此引出湖仓一体的解决方案。
二、湖仓一体定义
直观来看,湖仓一体就是把面向企业的数据仓库技术,与低廉的数据湖存储技术相结合,为企业提供一个统一的、可共享的数据底座,避免传统的数据湖、数据仓库之间的数据移动,将原始数据、加工清洗数据、模型化数据,共同存储于一体化的“湖仓”中,既能面向业务实现高并发、精准化、高性能的历史数据、实时数据的查询服务,又能承载分析报表、批处理、数据挖掘等分析型业务。
目前行业普遍认同的观点:湖仓一体需要打通数据仓库和数据湖两套体系,让数据和计算在湖和仓之间自由流动,从而构建一个完整有机的大数据技术生态体系。
湖仓一体方案的出现,帮助企业构建起全新的、融合的数据平台。通过对机器学习和AI算法的支持,实现数据湖+数据仓库的闭环,提升业务的效率。数据湖和数据仓库的能力充分结合,形成互补,同时对接上层多样化的计算生态。
目前,市场上主流的三大开源数据湖方案分别是: Delta、Apache Iceberg和Apache hudi。
Delta是Apache Spark背后商业公司Databricks推出的,国内互联网公司相对使用较少;Apache Hudi是一种针对分析型业务的、扫描优化的数据存储抽象,它能够使DFS数据集在分钟级的时延内支持变更,也支持下游系统对这个数据集的增量处理;Apache Iceberg是一种用于大型数据分析场景的开放表格式,目前社区关注度暂时比不上Delta,功能也不如Hudi丰富,但具有高度抽象和非常优雅的设计。
数澜科技旗下核心产品数栖平台支持基于Iceberg和Hudi构建数据湖,下面阐述数澜科技在湖仓一体方面的实践经验,主要包括技术架构、数据入湖、数仓构建。
三、湖仓一体实践
在数澜科技提供的湖仓一体解决方案中,数据统一存储在Iceberg+HDFS上,并用Flink、Spark、Trino三个不同引擎访问湖中数据来对外提供不同类型的服务。
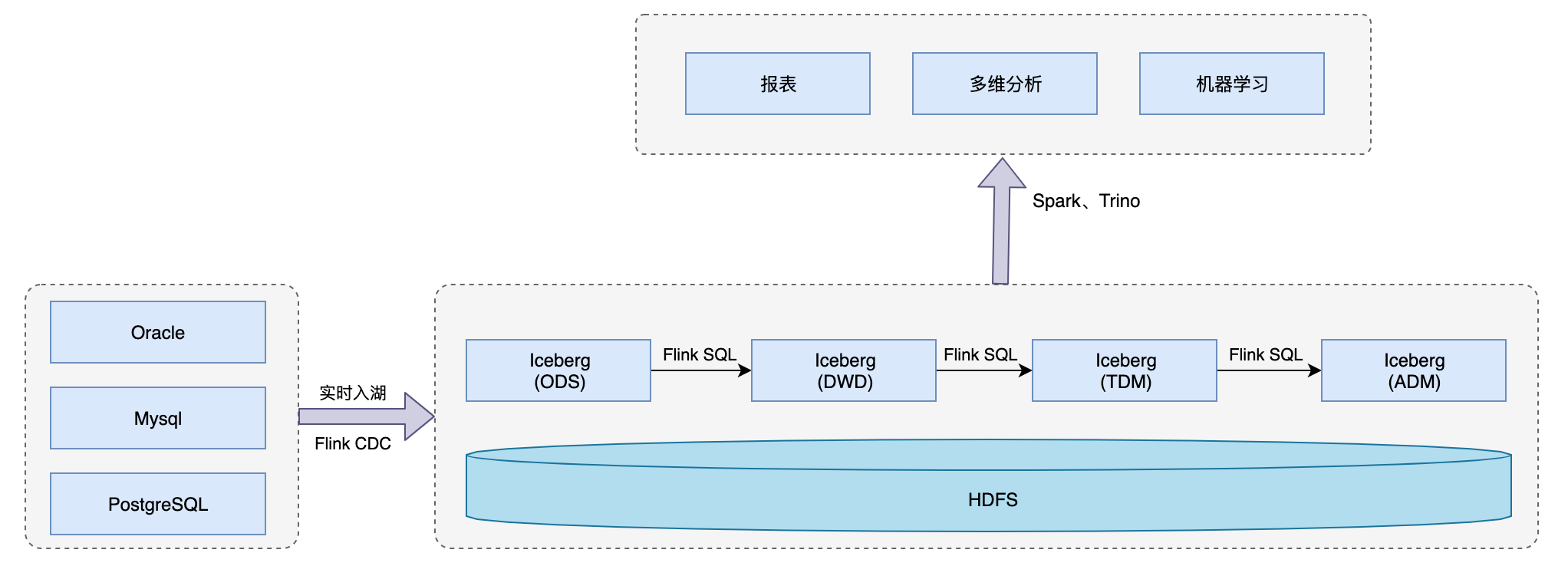
基于Flink+Iceberg来构建湖仓一体准实时数仓,将原来T+1的离线数仓做成准实时的数仓,提升数仓整体的数据时效性,以便更好支持上下游的业务。在数据仓库处理层,可以用 Trino进行一些简单的查询,而且 Iceberg 也支持 Streaming read,所以在系统的中间层也可以直接接入 Flink,用 Flink 做一些批处理或者流式计算的任务,把中间结果做进一步计算后输出到下游。
在具体实例中,把Mysql中的demo_users表数据通过Flink CDC实时入湖,落入数据仓库ODS层的表中,然后基于ODS层和一个实时流flink_demo_complaint_data进行Join操作生成DWD层的表。

示例代码:

CDC 数据成功入湖 Iceberg 之后,我们还会打通常见的计算引擎,例如 Presto(Trino)、Spark、Hive 等,他们都可以实时读取到 Iceberg 表中的最新数据。
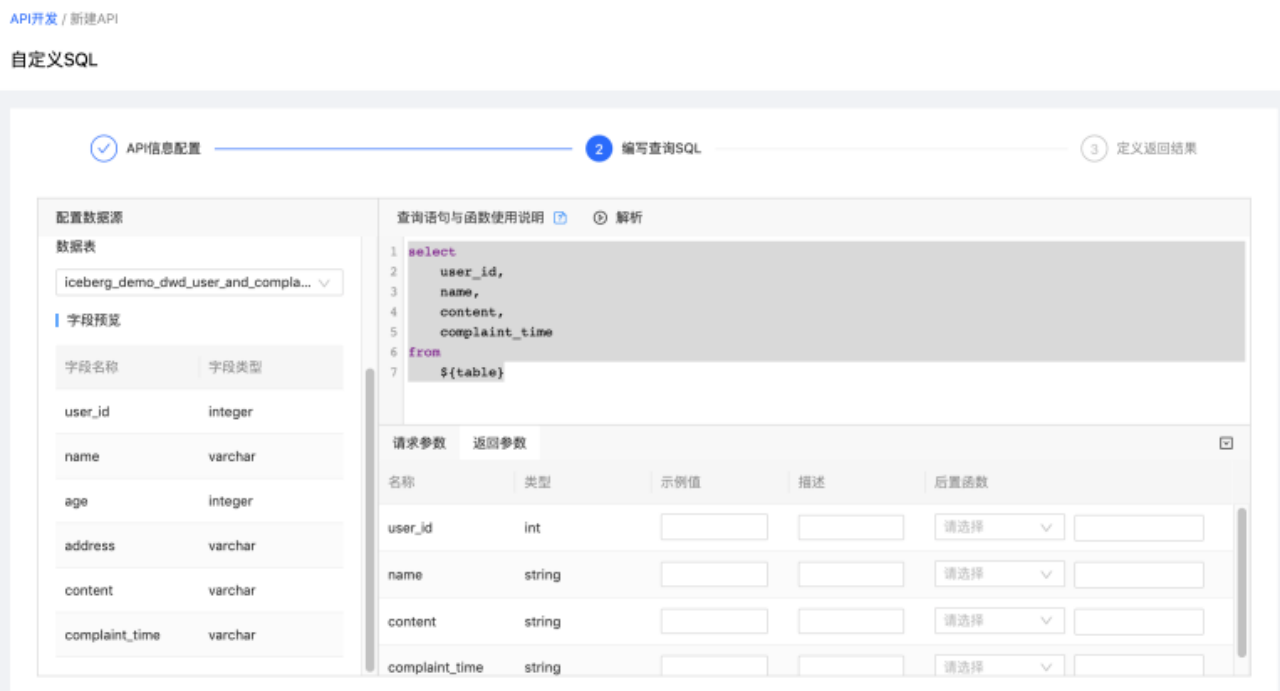
下图是基于Trino准实时查询Iceberg表中的数据,给业务方提供自定义SQL类型的API。
同时,针对目前市场上湖仓解决方案中普遍存在的痛点:缺乏数据缓存层,导致数据访问速度较慢;缺乏统一的编程模型,例如针对批和流要写Spark和Flink两种类型的SQL。数澜科技在数栖平台中引入Alluxio和Beam解决此类问题。
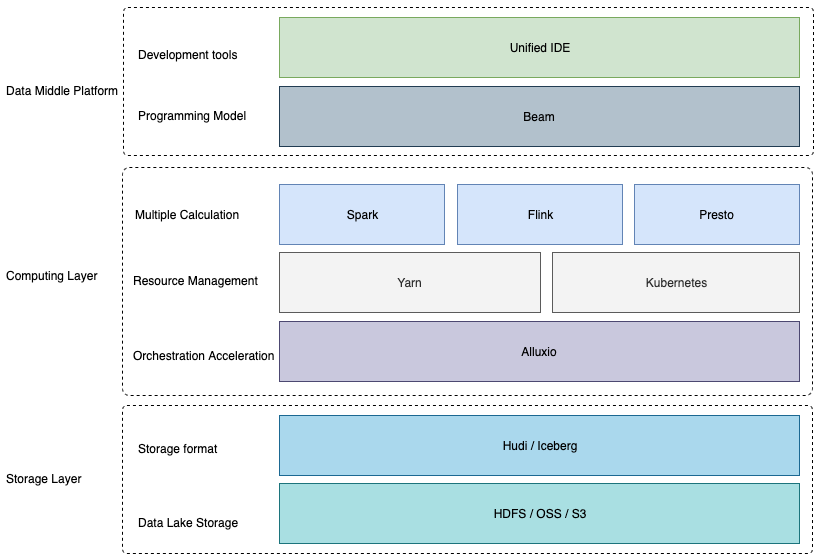
基于Alluxio进行数据缓存
在当前架构中,计算引擎层通过Iceberg或Hudi提供的API来操作底层的文件存储系统,导致数据读写速度较慢。因此,考虑引入Alluxio作为数据编排层。加速对数据湖的读写,当Spark、Flink或Trino当问文件系统时,Alluxio充当虚拟分布式存储系统来加速数据,并与每个计算群集共存。
基于Beam的统一编程模型
Apache Beam是一个开源的统一编程模型,统一流和批,抽象出统一的API接口。并且生成的分布式数据处理任务应该能够在各个分布式执行引擎(例如Spark、Flink)上执行,用户可以自由切换分布式数据处理任务的执行引擎与执行环境。因此后续计划引入Beam作为统一的编程模型,在数据中台产品层提供一个统一的IDE。






